



Primjena binomne razdiobe u cestovnom prometu
Prije nisam bio (veliki) obožavatelj binomne razdiobe. Dva razloga. Prvi, definiranje i računanje binomnog koeficijenta. Drugi, puno znakovitiji, je „bijeg“ od binarnih veličina. Stvarni svijet, odluke, život, …, nije crno/bijeli ili 0-1. Baviti se fuzzy logikom, podijeljenim strategijama, višekriterijskim odlučivanjem, to je “pravi izbor inženjera/ke” u modeliranju stvarnog svijeta. U doba dubokih neuronskih mreža, od detekcije različitih kategorija sudionika do percepcije okoline putem računalnog vida, bavljenje stvarima (stanjima, procesima) tipa 0-1 predstavlja „(pra)staru školu“.
Ipak, binomna razdioba je potrebna prometu. Ovdje ću se usredotočiti na cestovni promet, ali u svakom vidu prometa čitatelj(ica) može naći sukladnu ili sličnu primjenu. Zašto potrebna? Puno stvari u prometu ima binomnu prirodu/funkciju: crveno-zeleno ili zabranjen-slobodan-prolaz na semaforu, slobodno-zauzeto utovarno/istovarno skladišno mjesto ili mjesto za posluživanje na benzinskoj postaji, ili parkirno mjesto, zatvoren-otvoren cestovni objekt zbog vremenskih (ne)prilika, … .
Binarne veličine su i dalje potrebne (često i kritične) informacije/podatci u prometu, jer svaki sustav (model), pa i model umjetne inteligencije, treba takve elementarne podatke kao vjerodostojnu ulaznu veličinu. Uglavnom, ako imamo neki (1) konačan broj nezavisnih prometnih procesa s dva moguća ishoda i (2) svaki proces ima istu vjerojatnost uspjeha, onda trebamo binomnu razdiobu. Možemo proširiti temu na Poissonovu ili negativnu binomnu razdiobu i gledati kada je koja prikladnija. Ostat ćemo isključivo u okvirima binomne razdiobe.
Imamo:
- ograničen period promatranja,
- broj entiteta koji nešto čine u tom periodu,
- dolazak/pojavljivanje entiteta je podjednako (uniformno)
- proces se odvija na nekom kanalu posluživanja određeno definirano vrijeme,
pa moramo procijeniti s nekom vjerojatnošću (pouzdanosti) da će se nešto dobro/loše dogoditi. Krenut ćemo sa školskim, ali opet vrlo korisnim (i ilustrativnim) primjerom:
- promatramo istovar kamiona tijekom jednog sata,
- 20 kamiona pristiže u podjednakim vremenskim intervalima; ne trebamo dolazak modelirati posebnom razdiobom vjerojatnosti,
- istovar jednog kamiona traje 6 min,
- koliko istovarnih mjesta moramo osigirati da bi s 95 % vjerojatnosti mogli postići situaciju bez čekanja mamiona na istovar?
Vrijeme promatranja = 60 min
Broj kamiona = 20
Vrijeme istovara = 6 min
Vjerojatnost da je kamion na istovarnom mjestu je  pa je suprotna vjerojatnost (slobodno istovarno mjesto)
pa je suprotna vjerojatnost (slobodno istovarno mjesto)  . Vjerojatnost da „k“ kamiona bude na istovaru:
. Vjerojatnost da „k“ kamiona bude na istovaru:
![\[ B(k;n;p) = \binom{n}{k}\, p^{k}\, q^{\,n-k} \] \[ P(X=k) = \binom{n}{k}\, p^{k}\, q^{\,n-k}, \qquad k=0,1,\dots,n. \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-46dbb06fca809697fc1d0ce528b2bb7d_l3.png "Rendered by QuickLaTeX.com")
pa je suprotna vjerojatnost da više kamiona od nekog graničnog broja “x” bude na istovaru je:
![\[ P(k>x) = 1 - B(0; 20 ; 0,1) - B(1; 20 ; 0,1) - \text{...} - B(x; 20 ; 0,1) \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-b5692b004bf9b731180b91f8261d6584_l3.png "Rendered by QuickLaTeX.com")
Excel nam nudi funkciju =BINOM.DIST pa jednostavno možemo doći do odgovora,
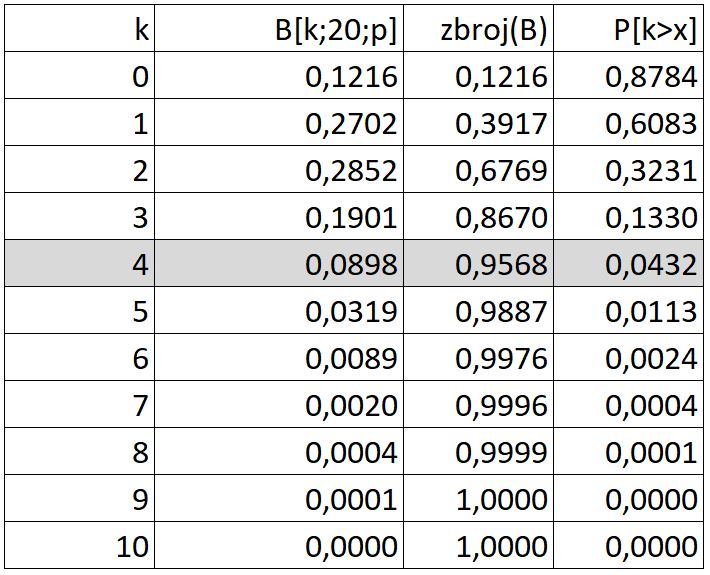
a odgovor je da pod opisanim uvjetima u skladištu s četiri istovarna mjesta postoji 95,68% vjerojatnosti da kamioni neće čekati na istovar. Kada bi imali 10 istovarnih mjesta mogli bi tvrditi da kamioni sigurno neće čekati na istovaru.
Mnogi će (ne)opravdano prigovarati da je ovaj (srednjo)školski problem nedostojan inženjerskog bloga. Moguće. A možda je bliže istini odgovor da su (srednjo)školski dani bili davno pa smo dosta toga zaboravili. Većina nas bi se prvo prisjetila Monte Carlo metode, krenula u avanturu modeliranja i potrošila puno vremena, a primjenom binomne distribucije bi riješili problem za pet minuta. Čistunci će reći da Monte Carlo može bolje modelirati stvarni život, prije svega neravnomjernost dolazaka. I za to postoji lijek. Recimo da zasigurno u 30 minuta dođe 12 kamiona, a osam u preostalih 30 minuta. Tada će vjerojatnost kamiona na istovaru biti  pa će izračun pokazati da pri vjerojatnosti 98,06 % kamioni neće čekati na istovar ako imamo pet mjesta. Ako ostanemo na četiri mjesta vjerojatnost je 92,74 %; manje od 95 % pa moramo promisliti. Ograničenje je naše znanje, iskustvo i snalažljivost (prilagodljivost), a ne “ograničenja” binomne razdiobe.
pa će izračun pokazati da pri vjerojatnosti 98,06 % kamioni neće čekati na istovar ako imamo pet mjesta. Ako ostanemo na četiri mjesta vjerojatnost je 92,74 %; manje od 95 % pa moramo promisliti. Ograničenje je naše znanje, iskustvo i snalažljivost (prilagodljivost), a ne “ograničenja” binomne razdiobe.
Isti model možemo primijeniti za procjenu broja izlaznih perona na autobusnom terminalu. Recimo da u kritičnih pet minuta (300 s) dolaze četiri autobusa i ne želimo čekanje autobusa. Ulazni podatak je prosječno vrijeme zadržavanja na izlaznom peronu 35 s (prilazak peronu, izlazak putnika, odlazak). U tom slučaju bi sa rješenjem jednog izlaznog perona imali 93 % vjerojatnosti da autobusi neće čekati na prilasku, a sa dva izlazna perona vjerojatnost se penje na 99,4 %.
Binomna razdioba nije nešto retrogradno i(li) zastarjelo, ona je zasigurno jedan od elemenata na kojima počivaju današnja rješenja. Ako neki model umjetne inteligencije odlučuje temeljem procjene vjerojatnosti nastanka nekog (ne)željenog događaja, onda se u pozadini (vrlo vjerojatno) nalazi binomna razdioba. Laički rečeno, sofisticirane aktivnosti umjetne inteligencije počivaju i na binomnim temeljima.
Da nije sve baš tako jednostavno, ali ni komplicirano, pokazat će jedan životniji primjer. Podatci su stari, ali opet dostatno dobri za ilustraciju mogućnosti primjene binomne razdiobe. Malo sam pretraživao i propitao ChatGPT i Perplexity o podatcima zatvaranja Masleničkog mosta zbog vremenskih neprilika. Na ovoj poveznici dobio sam stare podatke od 2008. do 2019. godine. Osim tih podataka, zabilježeni zapisi i vijesti web-portala upućuju da se zatvaranja najčešće dešavaju između rujna i ožujka. Događaju se i u ostalim mjesecima, ali vrlo rijetko, kao i što je vrlo rijetko da tijekom jeseni i zime nema zatvaranja.
Smjestimo se u 2020. godinu u neki logistički lanac i trebamo promišljati o redovitoj distribuciji između Dalmacije i kontinentalne Hrvatske. Poveznica s podatcima zatvaranja nudi dosta logičko strukturiranih podataka, ali opet nedovoljno za neki čvršći statistički utemeljeni zaključak. Kako razmišljati:
- zatvaranja se događaju tijekom cijele godine ili od početka rujna do kraja ožujka kako sugeriraju web-izvori,
- gledati odnos ukupno sati kada je most bio zatvoren za teretna vozila (7.127 sati) i ukupnog broja sati izabranog perioda,
- ili promatrati broj zatvaranja mosta jer svako zatvaranje mosta, bez obzira koliko trajalo, traži izmjenu itinerera jer roba treba doći do odredišta što prije, a rizik čekanja na otvaranje Mosta je prevelik.
Tri stvari su presudile da koristim broj zatvaranja: (1) moj (kognitivno pristran) stav zasnovan na dobrim vremenskim prognozama i osobnom uvjerenju (iskustvu) da zatvaranja nisu kratkotrajna, (2) činjenici da je prosječno vrijeme zatvaranja dulje od 12:45 sati što potvrđuje moju prethodnu “iz rukava” pretpostavku te (3) raspoloživo vrijeme za pisanje ovog bloga. Za period u kojem se dešavaju zatvaranja je od početka rujna do kraja ožujka; svake godine 212 dana bez prestupnih godina. Greška populacije je 0,12 % zbog izostavljanja ukupno tri dana prijestupnih godina.
Izjednačio sam broj zatvaranja s brojem loših dana za moj posao, što je opravdano i istinito: u danima kada je most zatvoren moj kamion ima veće troškove i dulji put. Imam 12 podataka, puno više od pet, ali opet puno manje od 30, što je pretpostavka korištenja trokutaste razdiobe. Trokutasta razdioba nam govori u utjecaju broja zatvaranja mosta zbog bure:
- min = 29 puta zatvoreno
- max = 68
- mod = 49
Vjerojatnost zatvaranja mosta na vrijednosti moda skupa je 0,051, matematičko očekivanje 48,7 i standardna devijacije 8,0. Mod skupa i matematičko očekivanje su vrlo bliski, što je i očekivano, budući je mod skupa podjednako udaljen od min i max vrijednosti. Malo manipulacije brojevima, kako sam pokazao u ovoj temi, daje nam sljedeće pokazatelje:
- kod 62 zatvaranja obuhvaćeno je 95,1 % svih zatvaranja,
- zatvaranja se događaju 212 dana godišnje.
- što upućuje da je vjerojatnost zatvorenog Masleničkog mosta tijekom jedne godine u periodu rujan – ožujak (za period 2008. – 2019.):
 .
.
Ako bi gledali čisto frekvencijski, u 12 godina (2008. – 2019.) od početka rujna do kraja ožujka ukupno je proteklo 61.128 sati (računajući i dane prestupnih godina), a most je bio zatvoren 7.127 sati pa je vjerojatnost (vrijeme) zatvorenog mosta 0,117. To je puno manje od prethodno izračunatih 0,293. Ostat ću pri većoj vrijednost jer izračun provodim s logističkog motrišta, a ne s motrišta teorije repova čekanja.
Prije izračuna moramo se prisjetiti ostalih važnih parametara normalne razdiobe; matematičkog očekivanja, varijance i standardne devijacije:
![\[ \mathbb{E}[X] = n\,p \] \[ \mathrm{Var}(X) = n\,p\,(1-p). \] \[ \sigma = \sqrt{\mathrm{Var}(X)} \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-9caa3c605dcb1bc5c10234c8a8c716ce_l3.png "Rendered by QuickLaTeX.com")
Želimo vidjeti situaciju u prosincu. Božićni blagdani su jedan od vrhova trgovačke sezone pa želimo distribuirati robu diljem Hrvatske, neovisno prevozimo li iz kontinentalne Hrvatske prema Dalmaciji ili obrnuto. Prosinac ima 31 dan, pa uz ostale prethodno izračunate parametre naš statistički model izgleda:
![\[ n = 31, \, p = 0,293, \, q = 0,707 \] \[ P(X=k) = \binom{31}{k}\cdot {0,293}^{k}\cdot {0,707}^{\,31-k}, \qquad k=0,1,\dots,31. \] \[ \mathbb{E}[X] = n\, p = 8,99 \] \[ \mathrm{Var}(X) = n\,p\,q = 6,4 \] \[ \sigma = \sqrt{\mathrm{Var}(X)} = 2,5 \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-4a36022b98f5f1c1900103700c4b8b9c_l3.png "Rendered by QuickLaTeX.com")
što nam pokazuje da će masa binomne razdiobe biti koncentrirana oko veličine 9 dana, uz jednu standardnu devijaciju od 2,5 dana, pa su zatvaranja mosta u intervalu [6,12] dana i najvjerojatnija. Budući bura ne pita vikende, a nedjeljom i blagdanima se ne vozi, ovi brojevi se mogu ponešto smanjiti, ali za to treba pogledati točno na kalendar zbog tri Božićna dana (od Badnjaka do Svetog Stjepana) i Stare Godine (31. prosinca) pa vidjeti šte se (ne) preklapa s nedjeljama. Ovo je ilustrativni primjer pa ćemo zanemariti utjecaje nedjelje i pesimistično zaključiti da nas bura gnjavi jedino radnim danima.
Sukladno modelu dolazimo do konačne istine glede prosinca, a ona je prikazana u sljedećoj tablici.
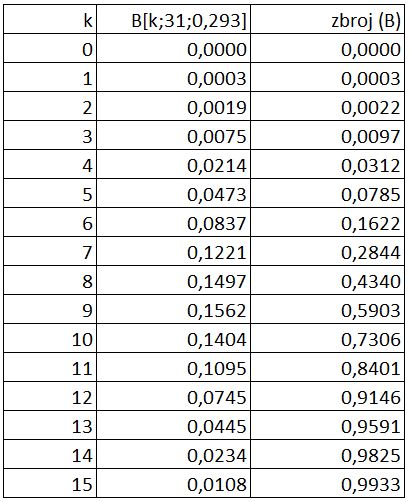
Iz tablice možemo konkretno zaključivati. Kolika je vjerojatnost da će Most biti zatvoren u prosincu barem pet i 10 dana?
![\[ P(X \ge 5) = 1 - P(X \le 4) = 1 - [P(0) + P(1) + P(2) + P(4) + P(4)] \] \[ P(X \ge 5) = 1 - 0,0312 = 0,9688 \] \[ P(X \ge 10) = 1 - P(X \le 9) = 1 - [P(0) + P(1) + P(2) + \dots + P(9)] \] \[ P(X \ge 10) = 1 - 0,5903 = 0,4097 \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-9ed7a952567c113943b4b6a7017db49a_l3.png "Rendered by QuickLaTeX.com")
Da ćemo pet radnih dana imati dulja putovanja vjerojatnost je gotovo 97 %, a jedino nas može “pomilovati” činjenica pokojeg preklapanja burovitog i neradnog dana. Za pola radnih dana u mjesecu imamo visokih 41 % vjerojatnosti da ćemo poslovati s povećanim troškovima i povećanim reputacijskim rizikom prema partnerima zbog (vrlo vjerojatnih) kašnjenja u nekim danima. Temeljem ovakvog modela možemo unaprijed procijeniti troškove većeg rada voznog parka. Ako prometujemo svim radnim danima i ne želimo kasniti, onda za barem 41 % putovanja moramo ukalkulirati dodatne troškove. Budući nam subote i nedjelje predstavljaju 25 % mjeseca, možemo i tih 41 % smanjiti na 31 %. Dobili smo vjerodostojan interval za operativno i(li) poslovno odlučivanje.
U stvarnom životu bili bi puno profesionalniji. Bilježili bi sve dane i vremena zatvaranja Mosta i stvarali svoju samostalnu bazu loših vremenskih uvjeta. Vjerojatno bi umjesto višegodišnjeg prosjeka stvarali vremenske nizove u mjesečnim koracima. Puno posla prije primjene binomne razdiobe, ali ako smo sigurni u njezine ulazne parametre tada je sve puno točnije, jasnije i argumentirano naspram “stručnih” procjena.
Zadnji primjer je korištenje binomne razdiobe za procjenu pouzdanosti sustava umjetne inteligencije. Uspoređuju se dva sustava:
- sustav A ima tri agenta/senzora i funkcionalan je ako rade barem dva,
- sustav B ima pet agenata/senzora i funkcionalan je ako rade barem tri.
Vjerojatnost da pojedini agent/senzor radi je  , a
, a  je vjerojatnost kvara. Treba izračunati i usporediti pouzdanost ova dva sustava. Pouzdanost za sustav A:
je vjerojatnost kvara. Treba izračunati i usporediti pouzdanost ova dva sustava. Pouzdanost za sustav A:
![A ($n=3$, $M=2$): \[ R_A = P(K\ge 2)=\binom{3}{2}p^2 q + \binom{3}{3}p^3 = 3 p^2 q + p^3. \] $q=1-p$: \[ R_A = 3 p^2(1-p) + p^3 = 3p^2 - 3p^3 + p^3 = 3p^2 - 2p^3. \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-af34297a44198344354fa16a06cb3614_l3.png "Rendered by QuickLaTeX.com")
Pouzdanost za sustav b:
![B ($n=5$, $M=3$): \[ R_B = P(K\ge 3)=\binom{5}{3}p^3 q^2 + \binom{5}{4}p^4 q + \binom{5}{5}p^5 = 10 p^3 q^2 + 5 p^4 q + p^5. \] $q=1-p$: \[ R_B = 10 p^3 - 20 p^4 + 10 p^5 + 5 p^4 - 5 p^5 + p^5 = 10 p^3 - 15 p^4 + 6 p^5 \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-fec5bee8e7d3a3ae15310b2a0802bc00_l3.png "Rendered by QuickLaTeX.com")
Uspoređujemo dva sustava:
![\[ R_A - R_B = (3p^2 - 2p^3) - (10 p^3 - 15 p^4 + 6 p^5) = \] \[ &= 3p^2 - 2p^3 - 10 p^3 + 15 p^4 - 6 p^5 = \] \[ &= 3p^2 - 12 p^3 + 15 p^4 - 6 p^5 \] \[ R_A - R_B = 3 p^2 \big(1 - 4p + 5 p^2 - 2 p^3\big) \] \[ R_A - R_B = 3 p^2 \big(1 - p\big)^2\big(1 - 2p \big) \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-231c89a464327466762589bff72237b3_l3.png "Rendered by QuickLaTeX.com")
Faktor  je uvijek
je uvijek ![\ge 0 \,, p \in [0,1]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-e1cfd6b1ad66c9202210872d669005eb_l3.png "Rendered by QuickLaTeX.com") . Jednak je nuli samo za rubne vrijednosti
. Jednak je nuli samo za rubne vrijednosti  .
.
Predznak  ovisi o faktoru
ovisi o faktoru  :
:
![\[ p < \frac{1}{2} \rightarrow (1 - 2 p) > 0 \rightarrow R_A - R_B > 0 \rightarrow \text{A je pouzdaniji} \] \[ p = \frac{1}{2} \rightarrow (1 - 2 p) = 0 \rightarrow R_A - R_B = 0 \rightarrow \text{jednako pouzdani} \] \[ p > \frac{1}{2} \rightarrow (1 - 2 p) < 0 \rightarrow R_A - R_B < 0 \rightarrow \text{B je pouzdaniji} \]](https://lanovic.eu/wp-content/ql-cache/quicklatex.com-2d1bba50fbcfb21347b5ac746dd88a5a_l3.png "Rendered by QuickLaTeX.com")
Znamo da su ICT sustavi na razini pouzdanosti većoj od 90(95) % pa bi dobar izbor bio sustav B. Današnja cjenovna dostupnost komponenti olakšavaju izbor većeg broja komponenti, jer je cijena odavno prestala biti presudan čimbenik na osnovnoj razini (basic) ICT rješenja. Pregledom usporednog grafa nameće se pitanje izbora sustava B, jer je razlika pri razinama pouzdanosti 95 % i višima jako mala; 0,6 % u korist sustava B.
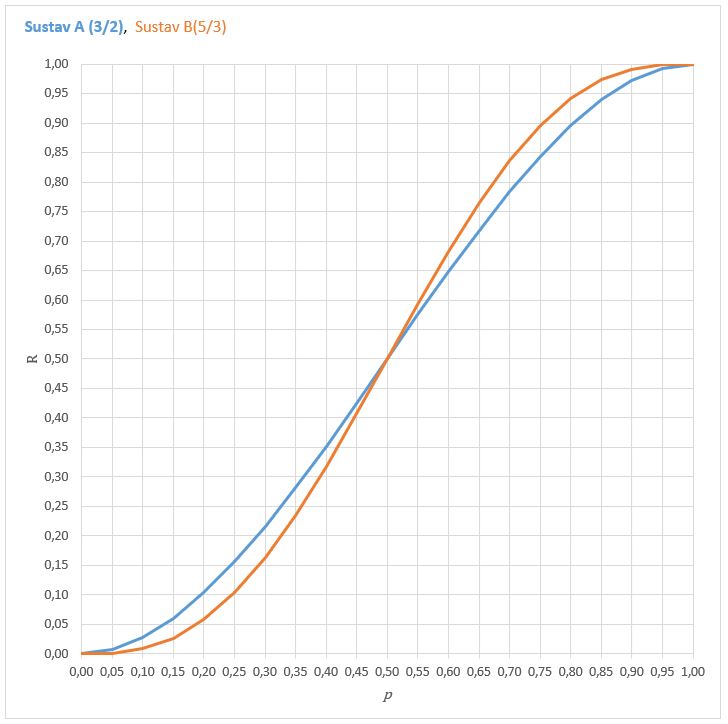
U jednoj godini s 250 radnih dana tih 0,6 % čini mogućih 12 radnih sati problema (zastoja) pa svatko može zaključiti isplati li mu se riskirati jedan i pol radni dan za nekoliko EUR skuplje rješenje.
Koliko god bili napredni, gradili modele strojnog učenja, promišljali inteligentne sustave (rješenja) zasnovane na dubokim neuronskim mrežama, transformerima, složenim optimizacijama i generativnim modelima, ovakvi osnovni (bazični) alati, tipa binomne razdiobe, i dalje će biti nezaobilazan arsenal sposobnosti (nad)prosječnog prometnog inženjera. Sve se u prometu u esenciji problema svodi na: (ne) radi, (ne)ispravno, dozvoljeno/zabranjeno, slobodno/zauzeto, (ne)točno i sve to vodi do korištenja binomne razdiobe. U svakodnevnom životu, stvarnom ili svijetu umjetne inteligencije, pouzdanost i redundancija jesu i bit će ključni pojmovi. Svi smo opčinjeni autonomnim vozilima, ali sumnjam da bi itko sjeo u takvo vozilo s nominiranom “zanemarivom” greškom oko 1 %. Svaki test modela strojnog učenja ima rješenja tipa (ne)točno ili (ne)prihvatljivo, a za definiranje intervala točnosti/preciznosti koristimo i binomnu formulu. Općenito, u današnjim ICT rješenjima ili rješenjima koja se već s pravom tituliraju umjetnom inteligencijom na dnu piramide i dalje postojano i pouzdano stoje modeli binomne razdiobe.
A gdje je binomna razdioba u korisna u svakodnevnom životu inženjera pokazala su prva dva primjera






